Falls are the leading causes of injury and death in elderly individuals. Here we introduce a computer vision based system using a Convolutional Neural Network to detect when a person falls, along with Deep Learning Audio Classifier which detects fall sounds. Our Android and IOS apps will be available for users and alerts when your dear ones are in trouble.
Prototype :
We use MediaPipe which offers open–source cross–platform, customizable ML solutions for live and streaming media. Which gives better performance and works better in small CPU devices. Used OpenCV a real–time optimized Computer Vision library for getting user video. The fall model could successfully run on Raspberry Pi 3 and detect a person falling successfully.
In addition to this, we added Deep Learning Audio Classification that differentiates a person’s falling sound from other sounds. We first preprocess the data to extract the audio signal’s relevant features using Mel frequency cepstral coefficients (MFCC) and then pass those important features through the Tensorflow Keras neural network for the audio classification.
Product :
We are developing a Convolutional Neural Network (ConvNet/CNN) using Pytorch that can identify when a person falls. PyTorch is an open-source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing. We used the Nvidia Jetson Nano is a small, powerful computer designed to power entry-level edge AI applications and devices. Which runs on a quad-core ARM Cortex-A57 64-bit @ 1.42 GHz, 4/2GB Ram, 128 CUDA core GPU, based on the Maxwell architecture. Videos can be understood as a series of individual images, and therefore we can treat video classification as performing image classification a total of N times, where N is the total number of frames in a video. Conventional 2D CNNs are computationally cheap but cannot capture temporal relationships; 3D CNN-based methods can achieve good performance but are computationally intensive, making them expensive to deploy. In this project, we used a Temporal Shift Module (TSM) by Ji Lin, Chuang Gan, and Song Han, that enjoys both high efficiency and high performance. Specifically, it can achieve the performance of 3D CNN but maintain 2D CNN’s complexity. TSM shifts part of the channels along the temporal dimension; thus facilitating information exchanged among neighboring frames. It can be inserted into 2D CNNs to achieve temporal modeling at zero computation and zero parameters. TSM is accurate
and efficient.
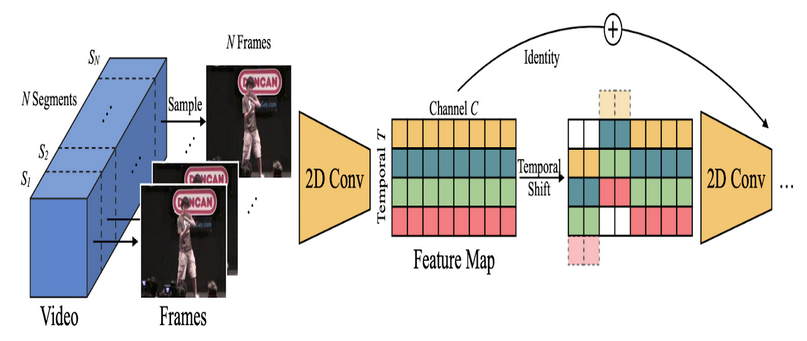
The final product should be able to get user video from Jetson nano webcam and OpenCV, a real–time optimized Computer Vision library. And feed to pre–trained CNN Classifiers and distinguish normal activities from a fall. The Deep Learning Audio Classification built–in prototype state can be integrated to give an additional confirmation, by picking up any falling sound. Then the mobile apps along with the firebase database can give the real–time alert.